親ページに戻る
Amazon.co.jp実測データの確率ランキング過程の理論的結果への統計的当てはめ
数学と実測を統計的につきあわせるということに興味のあるかたのために,
具体的なことを紹介します.
1. Amazon.co.jp実測データ
|
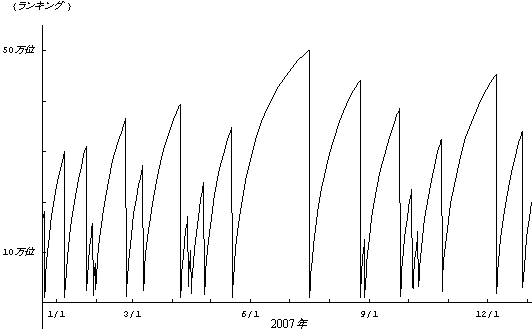
左図は,親ページの上のほう「ランキングの時間発展」の項の模式図の再掲です.
「ヨットの帆」のような曲線がたくさん並んでいますが,
その「帆」1個分のランキングの実測データ(某書籍が1部売れてから
次に1部売れたときまで)を
確率的ランキング過程の理論曲線に当てはめたのが左下の図です.
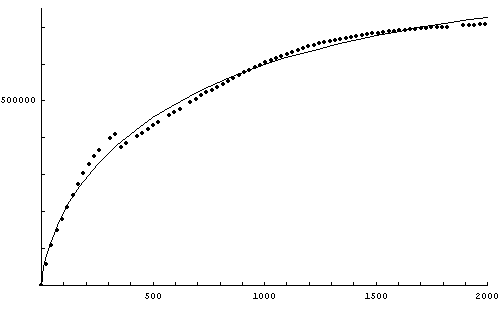
黒丸は Amazon.co.jp で某書籍のランキングの時間変化を
実測して得たデータ,77個の値です.横軸は時間,縦軸はランキングの数値.
重ねて実線で描いてある曲線は確率的ランキング過程の理論的結果.
|
|
77個の実測データ(黒丸)は2007年5月末から8月下旬の約3ヶ月,
約200時間の期間に24時間毎,ほぼ毎日21時に実測したランキングの数値です.
黒丸が完全な等間隔でなく,ところどころ抜けているのはセミナーの歓迎会や
抜けられない雑用などで21時にAmazon.co.jpのランキングを見に行けなかった日々.
350時間目に数千位ほど減っている(黒丸を滑らかにつないだグラフを
想像すると,不連続な変化)のが目につきますが,
当時Amazon.co.jpは棚卸しなどの在庫管理を手作業で行っていて,
絶版などで登録から外すべき本を手作業でまとめてやっていたのではないか,
それがたまたま測定に引っかかったのではないか,と推測しています.
|
2. ランキングの時間変化に関する理論的帰結の概要
実際のランキングが確率ランキング過程に合うと認めていただくとして,
理論曲線を具体的に描くには,現実から一つ情報を持ち込む必要があります.
全体として本がよく売れれば(確率ランキング過程の言葉で言えば,
先頭にジャンプする粒子が多ければ)売れない本はどんどん順位を下げるので,
曲線(図の弧の部分)の傾きは急になるし,
全体の売れ行きが悪ければ順位が下がらないので,曲線は横軸に平行に近く
寝た状態になります.
つまり,曲線の具体形は,Amazon.co.jp全体の本の売れ行き状況によって
変わります.
個々の本の売れ行き(本の個人情報とでも言うべき,個別の書籍の情報)
は不要ですが,売れ行きの分布
(モデルの数学的定義と結果のページのλ)
に,曲線の形は依存します.理論によれば,逆にλが決まればランキングの時間変化
は決まります.より詳しく言うと,
ランキングの時間変化は時刻tの関数として
見たとき,分布λのラプラス変換(分布の母関数)になることがわかっています.
親ページに,玉が飛ぶアニメを用意しましたが,そこの赤い玉は青い玉に
比べて平均で2倍頻繁に先頭に飛ぶ(本で言えば,青表紙のシリーズに比べて
赤表紙のシリーズは2倍良く売れる,という状況)ようにしてあります.
これは分布λとして,
『ジャンプ率(本の売れ行き)1のものが0.5 (50%), 2のものが0.5 (50%)』と
いう分布を選んだ,ということです.
実際にはλを連続分布とみなせるくらいいろいろな売れ行きの本があって,
売れ行きの大きいベストセラーは種類が少なく(小さな分布),
売れ行きの小さい専門書や人気の無い本は多数(大きな分布)あります.
もちろん,λは売れ行きの分布ですから,Amazon.co.jpは把握している情報です.
だから会社が教えてくれれば,わざわざランキングから情報を引き出す必要は
ありませんが,会社は教えてくれないのでランキングの時間変化から
逆算してλを手に入れよう,という次第です.
実際,数学的には,
時刻の関数としてランキングの曲線が得られればラプラス逆変換によって
λを逆算できます.
実際の場面での問題は,曲線が数学的意味で完全にデータとして得られる
わけではなく,有限個の点(上図では77個の時刻でのランキング)の値だけ
しか得られないことです.これは観測上の都合だけではなく,
Amazon.co.jpは1時間に1回しかランキングを更新しないので,
原理的に有限個の点での値しか得られません.
数学的にはこれでは入力として不十分ですが,
このような場合の確立した手段として,
データに基づく統計的推測を行います.
すなわち,未知の分布λ(Amazon.co.jpでどの程度売れる本が何割あるか,
という分布)の形を数個のパラメータを除いて決めておいて,
実測した有限個のデータがもっとも合うようにパラメータを決めることを目指そう,
というものです.
データと無関係に先にλの概要を決めるので,
残ったパラメータをどう調整してもデータを完全に再現することはできません.
しかし,残されたパラメータを最適化して得られたパラメータの値自体を,
対象とする現象(今の場合は本の売れ行きの分布)に即して解釈することで,
真のλの中から現実において重要な性質を抽出することができると考えます.
変分法をご存じならば,統計的当てはめは,試行関数を選ぶことに相当します.
最小化すべき「エネルギー」は,もっとも単純な最小2乗法では
データと理論値の2乗偏差の和をとります.
データを採取した各時刻での統計的ばらつきが評価できる状況
では,2乗偏差を分散で割ったものの和(カイ平方)を最小化します.
データ数が十分大きければ中心極限定理によってカイ平方を最小化する
方法は尤度と呼ばれる分布密度の積を最大化する方法と
漸近的に等結果を与えることが知られています.
Amazon.co.jpのランキングのデータに話を戻します.
求める分布λは,Amazon.co.jpが登録する書籍の購買頻度の分布です.
社会学等ではこのような社会的活動の活発さの分布を
べき法則(Pareto分布)で記述するのが普通です.
Pareto分布は,最低購買頻度(少しでも売れる本のうち,
いちばん売れ行きの悪いものの売れ行き)a と,
平等性の指数 b の2つの正のパラメータを持っていて,
λ([w,∞))=min{ (a/w)b , 1 }
で定義される分布です.
べき法則なので,売れ行きの良いベストセラーから売れない専門書まで
さまざまな売れ行きの本が混在することを表します.その上で,
bが大きいほどa付近に集中する状況を表すので,
ベストセラーの寄与が小さい,つまりロングテールが重要であり,
bが小さいほどwの大きいところ,つまりベストセラーが売り上げに効く
ことを表します.
詳しくは原著論文に譲りますが,
売り上げへの寄与という点では,b=1が境目になります.
ロングテール,すなわち,あまたある売れない本が,
Amazon.co.jpの売り上げの重要な部分を占めるのはb>1の場合であり,
b<1ならばベストセラーが売り上げの大部分を占める,
ということが具体的な計算からわかります.
3. 結論: Amazon.co.jpはロングテールビジネスではない
売れ行き分布λをPareto分布とした場合の実測データ(上図の黒丸)の
確率ランキング過程の理論的結果への統計的当てはめを実際に数値的に行うと,
最小2乗法とカイ平方当てはめでそれぞれb=0.63とb=0.77を得ました.
パラメータとしては,最低売り上げaと,以上の説明では省略しましたが,
総冊数Nの3パラメータになります.Nは80万冊程度,
aは3ヶ月あたり1冊程度,と自然な数値を得ました.
統計的手法(何を最小化するか)によって値は変わりますが,いずれも
b< 1 であることが重要です.
上で説明したように,これは,Amazon.co.jpの書籍総売上は
圧倒的に上位のベストセラーのわずかな冊数が支えていて,
ロングテール側のあまたある書籍は束になっても総売上には微々たる寄与しかない,
ことを明白に意味します.
ウェブ時代のロングテールビジネスの草分けとして宣伝されてきた
Amazon書店は(少なくともその日本版Amazon.co.jpは),宣伝に偽りありで,
普通の町の書店と同じく,少数のベストセラーが支える本屋であることが
わかりました.
4. 最後にいくつかの「青年の主張」
結論は以上ですが,最後に,結論の正当性に関わるいくつかの注を加えておきます.
-
『確率的ランキング過程のような単純なアルゴリズムをAmazonのランキングが本当に
使っているのか?』という質問を研究発表のたびに受けます.
『現実(Amazon)がそんな単純なはずはないだろう?』という当然の疑問.
これについては,上図がまさにお答え.
理論とデータが合う,
これはこの単純なモデルの定義を実際の現象の法則として良い,
ということそのものです.
仮にAmazon.co.jp自身が『複雑な定義で計算している』と内心思っていても,
現実にグラフが合うから,単純なモデルで現実のランキングの定義として良い
(数学的に等価)となります.
-
『上の図は上がりっぱなし?時々ジャンプするのでは?』と
(たぶん内容がわからなかったレフェリーに)聞かれました.
上の図の前後のデータも合わせて約1年分掲げたのが下の図.
横軸は通し時間,縦軸はランキング.
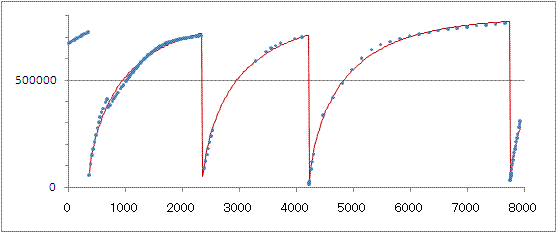
最初の売り上げ日(300時間目付近の1位近くへの飛び)が2007年5月末,そこから
2つ目の飛び(2300時間目,2007年8月下旬)までのデータがパラメータを決める
のに用いた上図の部分,残りの飛びは2007年11月中旬と2008年3月下旬.
曲線は,上で決めたパラメータとデータから読み取れる売上日を用いて
描いた理論曲線.パラメータを決めるのに使わなかったデータもなかなかよく合う
ことがわかります.
(付記:なお,上記のデータを取った頃から約2年後,Amazon.co.jpは
ランキングのアルゴリズムを変更して複雑にした模様です.
その後の継続的データ採取で判明したことですが,データ採取方法の進展については
項を改めて書くつもりです.また,その場合でも,
ロングテール,すなわち,あまたあるほとんど売れない本,
のランキングについては,単純なモデルが有効である可能性が高いです.)
-
「どの本を実測したのか」と質問されることがありますが,
確率的ランキング過程の項で説明したように,
曲線の具体形は注目する本の売り上げとは無関係で共通の形状です.
-
ランキングの時間変化から会社の売り上げ状況を分析する意義は何か?
もちろん,全てのデータを握っているAmazon.co.jpから情報をもらえるならば,
ランキングのデータを分析するまでもありません.
実際は,このページの冒頭近く,背景の項に書いたように,
オンライン小売業は,業績状況を(関係者や研究者にも)教えてくれません.
他方,ランキングはウェブ時代のロングテール型商売の象徴としてAmazonが
提示したいデータです.
たくさんの種類の商品を地価の安い倉庫に持っていて,
そのカタログをウェブといういまや安価となった「商品陳列棚」に持っている,
というのがウェブ時代のロングテール型商売の基本構造(ビジネスモデル)
とされてきたので,その象徴としてのランキングの数値は宣伝効果があるからです.
教えてくれるデータから隠されたデータを知る上で,
数学的なモデルが有効であるというのが,
確率的ランキング模型のオンラインランキングへの応用の意義です.
親ページに戻る
